
核心目标
可读性
程序员早已习惯看到各式各样的括号[,{,(,<,以及例如“void”或者写一个“f”或“0x”在一个数字边上。然而,这种表达方式并不自然,也是学写代码的新手常常犯错的地方。在GumboScript中,我们用非常基本的名词,动词,一些代数以及一些缩略语来涵盖其他的数学运算。
一个位操作(bitwise)中的match我们写作MATCH,一系列的属性(attribute)是用逗号分隔开来,而不是“bitwise or”。嵌套(nesting)就用空格来完成。动词总是写在名词前面,形容词和操作符(operator)共同使用形成方程式。我们希望新的语言读起来能够更像英语语句而不是特别技术向的用语。
我们的可读性比较高的语言借鉴了Lua和Python,还有一个由Chris Busch在1990年开发的大小仅为70KB的游戏“Warbots”。Warbots的目标就是用脚本写出一个可以战斗的机器人,但是只用最基本的逻辑知识,要求最少的格式,以及例如移动,射击,扫描等简单命令。
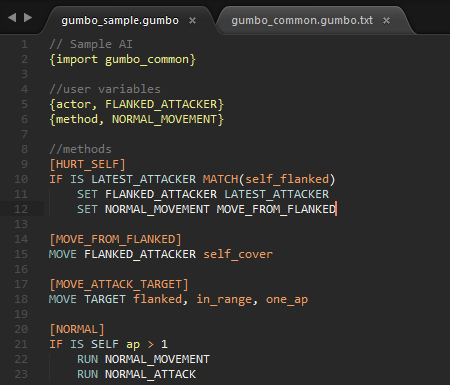
Warbots的pascal(上)和暗影狂奔(下)的GumboScript之间的比较。 Warbots: https://archive.org/details/Warbots
可失败性
有些时候,失败是有意为之的,另外一些时候则是完全出人意料的。但不论是哪种情况,AI控制的单位应该都能“优雅”地应对。在GumboScript里,每一种行为都有三种情况:通过(Pass),失败(Fail),繁忙(Become Busy)。用一些debug工具,我们能够检测到在某一个环节的某一个动作上出现了“失败”这种情况,并且设计者能够根据需要写出对应环节AI的应变行为。举个例子,如果游戏里的一把枪射击失败了,AI可能会进行上弹动作,或者直接轮着拳头上阵。
可持续性
当一个AI开始思考,它应该要记得所以关于自身行动和战场扫描结果的信息,很多时候队友的信息也要记住。在AI的记忆(Memory)里,我们加了一些例如“最后攻击的单位”或者“射程最大的武器”等条目。除此之外,设计师还能自己定义能被储存起来的变量。一个脚本可能会记录AI身上最有用的道具,或者某一个想要从侧翼包抄的敌人。在之后的环节中,AI能参考上述的因素来做出最后的决定。在AI设计领域,这种想法虽然已经出现了很久,但是在我们的脚本里充当了重要的角色。因为设计者能够决定AI应该记住哪些东西。
事件驱动
对于即时的AI来说,有很多事件会促使它们重新思考它们的行动。回合制里的AI能做成只在回合一开始考虑一次,但是我们希望我们的AI有更多的控制和更加及时的反应。目前我们做到了让脚本对一些事件做出反应(例如友军受到攻击,陌生人走进视野)。于是设计师可以在一个回合内制定一系列的事件来满足他们的设计需求,而不是只能等到下一个回合。
限制性
虽然我们想做出尽可能弹性,富有变化的系统,但是我们也同样希望快速和安全。这就是为什么有些运算符不会出现在脚本里。目前我们设定了一个默认的循环(loop)最大值,3。所有威胁的距离和可见程度只会在AI控制单位的位置变化时在AI内部进行估值。对于外部世界的扫描和内部自身能力与属性的评估会在回合时开始被保存到缓存里,之后只会在必要的时候重新评估。这让AI脚本在进行多次复杂的选择和评估的时候不会去触及那些耗时很长的东西。
Debug
在基本概念和代码确定下来后,我们开始着手设计游戏里的敌人。我们设计的初衷是要让AI“看起来不傻”。虽然这种说法听起来很随意,但也是一种很实际的看待AI的角度。最重要的一点就是在玩家眼里,AI是怎么样的。
以下是我们为了游戏里最常见的AI,战士,所设计的战斗方式的图表。
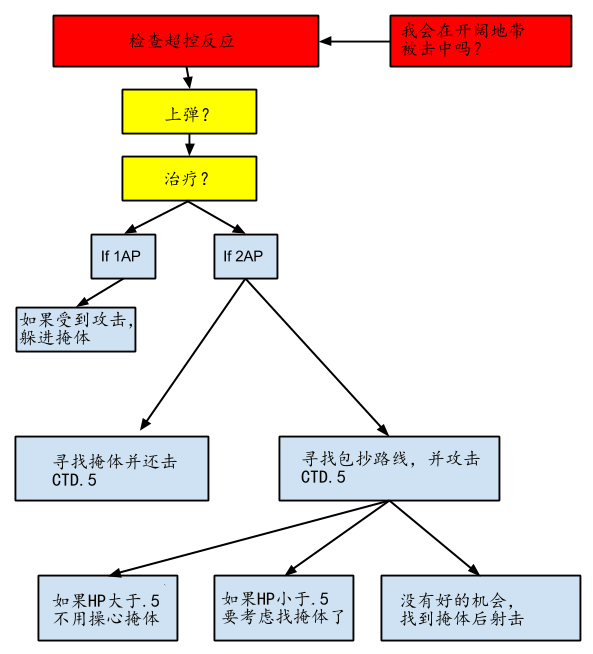
这个图表在每一个AP(Action Point,行动点数)被用掉的时候会开始评估。这么做的原因是,AP的数量有很多种。普通的敌人一开始有两个AP,但战场上有很多事情会发生来减少他们手上的AP。因此我们不能保证AI会在评估阶段还有没用完的AP。
我们在开发时候在基础战斗模型上加入了很多新要素,然而中心思想一直是固定的。
超控反应(Reactive Overrides,红色)会在AI被迫做出反应,但是还没有轮到它们回合的时候发生,例如图表上显示的“在开阔地带被击中”。
特殊情况(Special Condition,黄色)是优先级第二高的。虽然和这个处理的不是性命攸关的事情,但也不容忽视。这一类的情况会按照优先级的顺序依次出现。这使得AI会做一些很重要的事情,却不会因此丢了性命。引入必要程度的自我保护是让AI“看起来不那么傻”的关键。
在通常的战斗环节中(淡蓝色)你会发现掩体十分关键。这也是让AI“看起来不傻”的很重要的一条。在一队如狼似虎的暗影跑者举着各式武器冲过来的时候,AI却还悠闲地站在开阔地带,这很明显能被算作“傻冒”。
我们还利用了人类的天性:他们喜欢在一些本没有意义的事情上去寻找意义。在图表里,CTD代表“Chance To Do(做某件事的几率)”,并且十进制的值被转换成了百分比。在图表中,AI有50%的几率找掩体并攻击,或者寻找包抄的路线。在游戏里的法师角色的设计中,CTD的应用更加广泛,而且这带来了不错的结果。举个例子吧。大多数时候法师都会等待时机,在多个敌人靠得比较近的时候施放范围技能。不过有些时候为了让游戏体验更有趣,他们也会挑选单独的目标施放技能。
超控,特殊情况按照优先级排列,另外还有一些随机战斗循环一起在玩家心目中营造出一个敌人有智慧的印象。
目标和执行
最初写设定时候的目标就是创造一个成体系的逻辑形式:让AI在任何情况下“看起来不傻”,不过实际做的时候完全不是这么弄的。我们后来发现了AI里的一个很大的问题,那就是AI会连续在两次重复躲掩体的动作,而不会做其他事情。说得好听点,这只是“有点奇怪”;说得难听点,“这个太二了”。例如,某一个AI控制的单位会
- 在前进过程中重复两次躲掩体的动作
- 在远离玩家的过程中,躲两次掩体
- 在前面没有人的情况下离开掩体,接着马上躲进去
为了贯彻快速与安全的指导思想,我们用了个简单粗暴的脚本。一旦一个单位进到掩体后,确保AI会做其他的动作,或者直接结束回合。这个脚本能在AI想要躲进掩体的时刻使用。AI要么真的躲进掩体后面,接着采取其他行动,要么结束回合。我们把这个脚本放在任何可能的分支上,而非更加系统地控制。这个原因在于上述行动排列组合的结果并不是什么很大的数目。
现在我们既然知道了地雷在哪里,那么一个更加成系统的掩体动作变得可能。当时由于发售日在即,我们选择了一个稍微稳妥点的设计。在一辆跑动中的火车上加装东西可能会很刺激,但是在火车飞驰的时候却要改变引擎的工作方式就显得太刺激了。
幸运的是,我们的掩体问题是唯一个比较大的游戏开发瓶颈。设计者们能够用新的语言来更加快速地对游戏AI做出更新。如果有人想在GumboScript的环境下做点什么改变,是非常方便和快捷的。这让开发者们能够有余力去注重AI新行为的设计和改进。结果就是更高质量的AI体验,但是更少的用在工程方面的时间。即使像暗影狂奔:龙陨这样开发时间短的游戏,优先研发一个合适的工具也得到了很不错的回报。
对未来的展望
龙陨里所应用到的GumboScript仅仅是一个开始。这个版本里我们仅仅考虑了对于基本回合制动作的支持。我们希望在使用度方面扩展已有的系统,加入更多的预测,目标导向(goal-based)的决策,以及学习能力。我们(Harebrained Schemes games)希望在之后的回合制或者即时战略游戏里能够出现反应更灵敏更迅速的AI。
如果你想研究一下基于目的的游戏,我们建议你看看Jeff Orkin在Goal Oriented Action Planning方面的作品。一些很先进的AI概念已经被用在诸如F.E.A.R.等第一人称射击游戏里。http://alumni.media.mit.edu/~jorkin/goap.html
如果你想试试我们的GumboScript,你可以在UGC Workshop里为龙陨创建自定义的内容。这是我们在Steam上的社区主页: http://steamcommunity.com/app/300550。 在公司内部,我们使用Sublime Text作为脚本编辑器并自定义语法高亮。关于这些的深入阅读请见我们的Wiki:http://shadowrun-returns.wikispaces.com/GumboScript.
于暗影中再会!少年!
译注:
- The original article was from Gamasutra, and was translated to Chinese by J_Lu from Beacon Labs.
- 欢迎转载,转载即意味着你同意了授权条款。商业机构转载须要事先得到作者授权,并且提供给作者转载的链接以供作者检查是否符合条款。